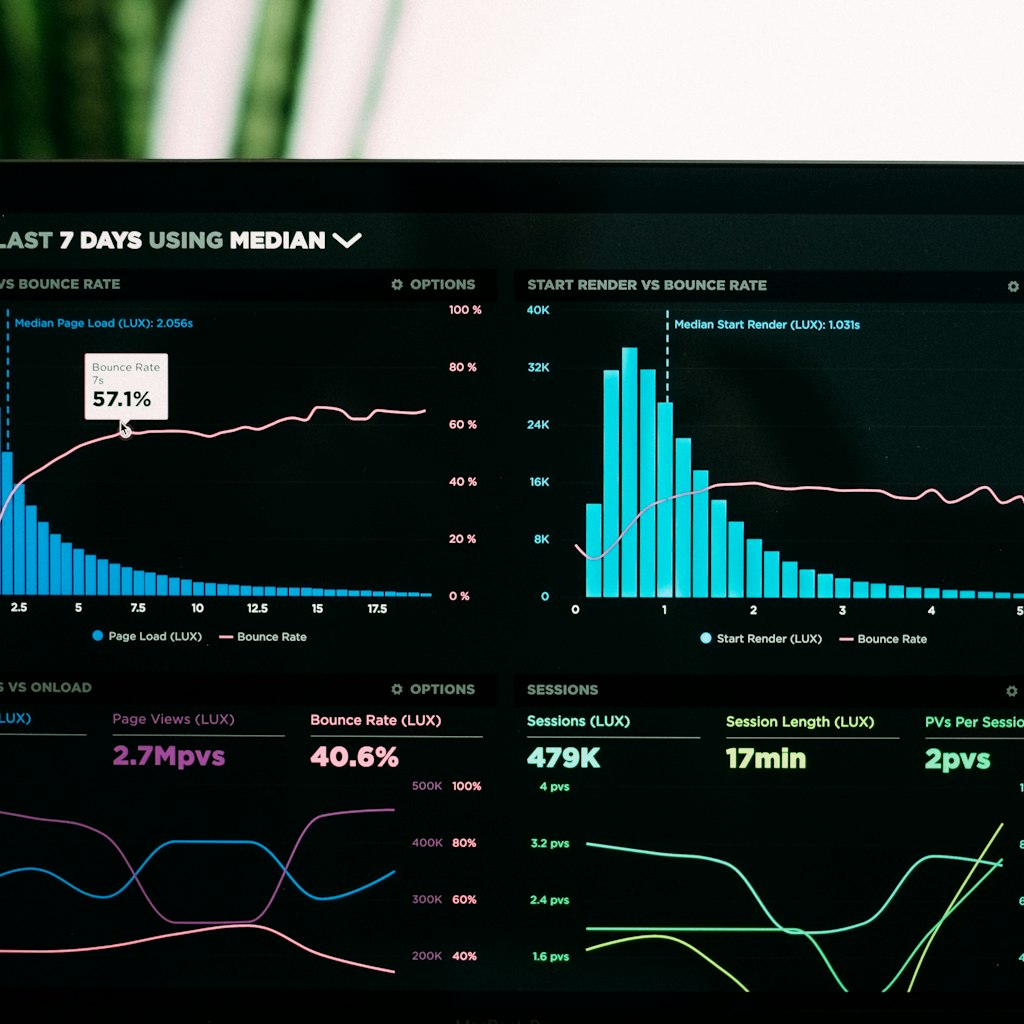
The Problem With Trusting AI
Large language models are impressive — but they are also unpredictable.
Two identical prompts can sometimes produce different answers. A model might generate a confident-sounding response to a question it has no business answering. It can hallucinate facts that sound plausible but are completely false.
This variability creates a critical problem for companies deploying AI systems at scale: how do you know whether an AI model is reliable enough to trust?
The answer lies in a growing discipline called LLM evaluation.
LLM evaluations are systematic tests designed to measure how language models perform across predefined benchmarks and datasets. Rather than hoping a model works, engineers now run thousands of automated tests before releasing models into production — tests that measure not just whether answers are correct, but whether they are safe, consistent, and useful.
This practice is quietly becoming as fundamental to AI development as unit testing is to traditional software engineering. Without it, deploying AI at scale becomes dangerous.
What Gets Tested
When researchers and engineers evaluate large language models, they measure performance across multiple dimensions.
Factual accuracy tests whether the model generates correct information. A model might be asked questions with verifiable answers — geography facts, historical events, scientific concepts — and its responses compared against ground truth.
Reasoning ability measures whether the model can follow multi-step logical arguments. Tests might involve word problems, mathematical proofs, or complex decision-making scenarios where the reasoning process matters as much as the final answer.
Safety evaluates whether the model refuses harmful requests, avoids generating toxic content, and respects user privacy. Safety tests are designed to probe edge cases where models might behave unexpectedly.
Consistency measures whether a model produces similar outputs for semantically equivalent inputs. If a model generates wildly different answers to variations of the same question, that inconsistency is a liability in production.
Hallucination rates specifically target one of the most dangerous failure modes: the model’s tendency to generate plausible-sounding but false information with high confidence.
Each dimension requires different testing approaches. Factual accuracy needs ground truth datasets. Safety needs adversarial prompts designed to trigger bad behavior. Reasoning needs complex multi-step problems. Consistency requires careful prompt engineering to create semantic equivalents.
The Rise of Evaluation Infrastructure
One of the most important evaluation projects is HELM (Holistic Evaluation of Language Models), developed at Stanford’s Center for Research on Foundation Models.
HELM evaluates models across dozens of real-world scenarios using a standardized methodology, measuring seven metrics — accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency — across 42 scenarios. The framework improved standardization from 17.9% to 96.0% of core evaluation scenarios and has become a de facto standard for comparing model performance across the industry.
OpenAI Evals provides a framework for evaluating models against custom task definitions. Developers can create task-specific evaluations, run them against models, and track performance over time. The framework has become one of the most widely adopted evaluation tools in the industry.
LMSYS Chatbot Arena takes a different approach: it allows users to chat with two anonymous models side-by-side and vote on which response is better. The crowd-sourced voting — now exceeding five million votes across more than 300 models — creates a ranking based on real-world preference rather than automated metrics, using an Elo rating system adapted from chess. The Chatbot Arena has become influential in how researchers understand which models actually perform best in practice, though recent scrutiny has raised concerns about large companies privately testing many model versions and only publishing their best results.
Anthropic’s evaluation framework emphasizes constitutional AI evaluation — training and testing models to follow explicit principles written into a constitution, using a combination of supervised learning and reinforcement learning from AI feedback (RLAIF). The approach measures not just performance but also alignment with intended values, enabling AI systems to generate useful responses while minimizing harm.
Advertisement
Why Evaluation Matters in Production
Without rigorous evaluation, deploying AI systems becomes a game of Russian roulette.
Consider the consequences of deployment failures:
Medical AI: A language model providing inaccurate medical advice could harm patients. Evaluations must verify that medical information is accurate and that the model recognizes the limits of its knowledge.
Legal research: An AI system generating fake case citations could mislead lawyers and undermine cases. Legal AI requires evaluations that catch hallucinations with near-perfect precision.
Financial analysis: An AI system providing incorrect market analysis could cost investors millions. Financial applications require rigorous evaluation of quantitative reasoning and factual accuracy.
Content moderation: An AI system incorrectly flagging or allowing harmful content could amplify abuse at scale. Moderation systems require evaluations that test both false positives and false negatives.
In each domain, the cost of an unreliable AI is not just a user’s frustration — it is liability, harm, or lost revenue.
This is why evaluation has become non-negotiable. Anthropic publishes extensive evaluation reports before releasing new models. OpenAI conducts red teaming where external researchers attempt to find failure modes. Google DeepMind evaluates models against safety criteria before deployment.
The Challenge: Evaluation Drift
A subtle but critical problem in LLM evaluation is evaluation drift — the tendency of models to become optimized for specific benchmarks rather than for real-world performance.
As models are trained, fine-tuned, or optimized against popular benchmarks like HELM or Chatbot Arena, they can learn to perform well on those specific tests without actually improving on the real-world tasks those benchmarks are meant to measure.
This creates a false sense of progress. A model can score higher on HELM while actually performing worse on novel, real-world tasks.
Researchers are addressing this through:
- Diverse benchmark suites — evaluating against many different benchmarks rather than optimizing for one
- Dynamic benchmarks — continuously updating evaluation datasets so models cannot memorize answers
- Real-world evaluation — testing models on actual deployment tasks rather than synthetic benchmarks
- Adversarial evaluation — having humans actively try to find failure modes rather than using static test suites
The Future of AI Testing
As AI systems become more autonomous and more integrated into critical systems, evaluation becomes increasingly important.
The next generation of evaluation frameworks will likely focus on:
Continuous monitoring — not just evaluating models before deployment, but continuously monitoring their performance in production to detect performance degradation.
Causality testing — understanding not just whether a model gives the right answer, but why it gives that answer, to catch reasoning errors that might lead to wrong answers in novel scenarios.
Robustness evaluation — testing how models behave under adversarial conditions, distribution shifts, and edge cases rather than assuming clean test data.
Human-in-the-loop evaluation — combining automated tests with human judgment to evaluate aspects of model behavior that are hard to quantify.
The leading AI research labs are already investing heavily in these directions. What was once an afterthought in model development — “we’ll test it when it’s ready” — has become a fundamental research area.
The Emerging Standard
For anyone building AI systems that will be deployed in production environments, evaluation has gone from optional to mandatory.
The standard workflow now looks like this:
- Develop model
- Run comprehensive evaluations across multiple benchmarks
- Identify failure modes
- Improve model or define failure boundaries
- Deploy with continuous monitoring
- Evaluate performance in production
- Update evaluations based on real-world failures
- Iterate
This workflow — development, evaluation, deployment, monitoring, improvement — is becoming as standard in AI development as the test-driven development cycle is in software engineering.
The engineers and researchers building reliable AI systems understand that a model is not ready for production until evaluations prove it is. And those evaluations must be rigorous, diverse, and continuous.
That discipline is what separates AI systems that work reliably from AI systems that fail unpredictably.
Advertisement
Decision Radar (Algeria Lens)
| Dimension | Assessment |
|---|---|
| Relevance for Algeria | High — Any Algerian organization deploying AI models needs evaluation discipline to avoid costly failures in healthcare, finance, or government applications |
| Infrastructure Ready? | Partial — Open-source tools like HELM and OpenAI Evals can run on modest hardware, but large-scale evaluation requires compute that most Algerian organizations lack |
| Skills Available? | No — LLM evaluation is a specialized discipline that requires ML engineering expertise rarely found in Algeria’s current talent pool |
| Action Timeline | 6-12 months — Algerian AI teams should begin integrating basic evaluation workflows into their development processes now |
| Key Stakeholders | AI development teams, university computer science departments, government AI strategy offices, Algerian startups deploying LLM-based products |
| Decision Type | Educational — Understanding evaluation frameworks is a prerequisite before deploying any AI system in production |
Quick Take: Algerian teams building AI applications should adopt open-source evaluation frameworks like HELM and OpenAI Evals immediately, even with limited resources. Running systematic evaluations before deployment is far cheaper than dealing with hallucination failures or safety incidents in production, especially in sensitive domains like Arabic-language government services.
Sources & Further Reading
- HELM: Holistic Evaluation of Language Models — Stanford CRFM
- OpenAI Evals: A Framework for Evaluating LLMs — GitHub
- LMSYS Chatbot Arena: Benchmarking LLMs with Crowd Preferences
- Anthropic Research: Constitutional AI and Evaluation — Anthropic
- Red Teaming Network — OpenAI
- Model Evaluation at Scale — Google DeepMind
🔗 Related Intelligence

AI Hallucinations: Why Language Models Still Lie and What Is Being Done About It
The Multi-Agent Myth: Why More AI Agents Can Actually Make Systems Worse
The LLM Benchmark War: Why AI Leaderboards Are Broken and What Actually Matters
LLM Evals: Why Testing AI Became the Hottest Skill in Tech






Advertisement